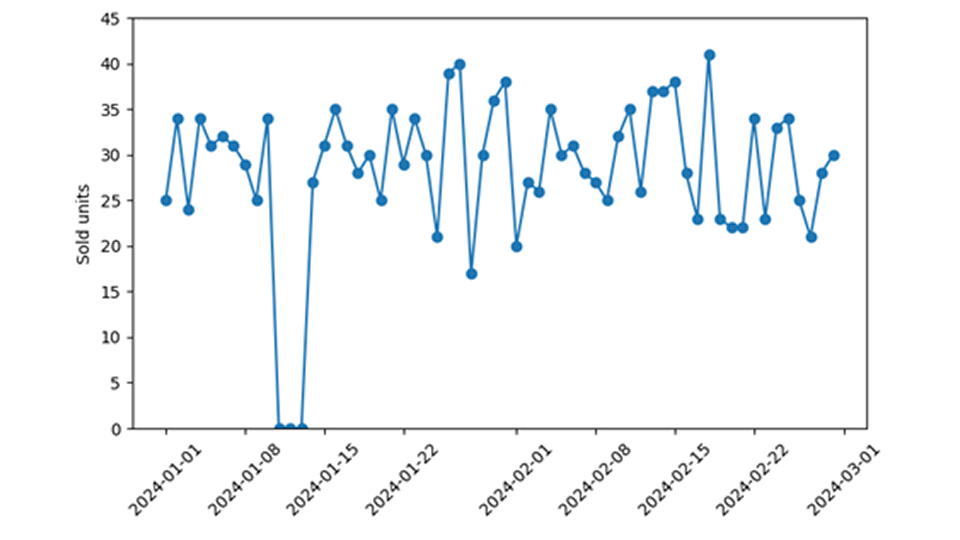
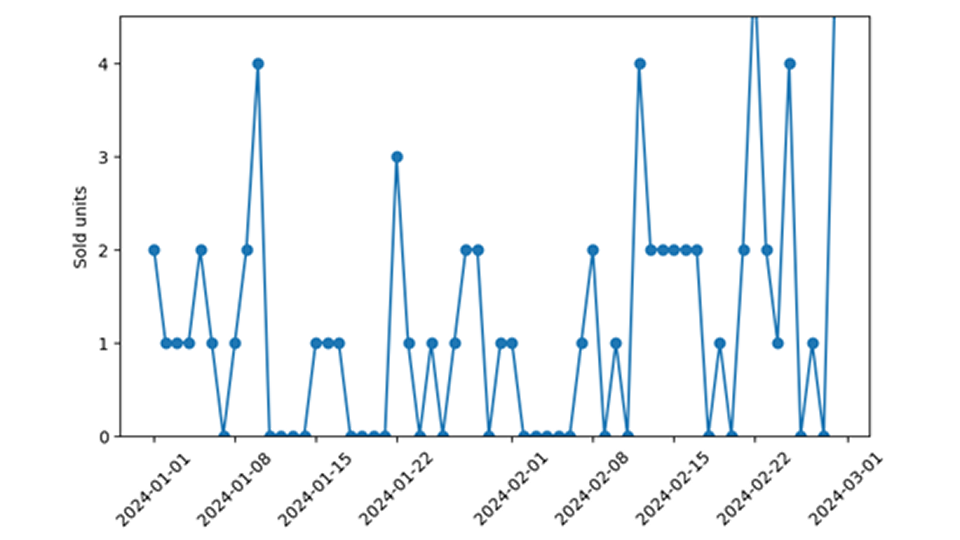
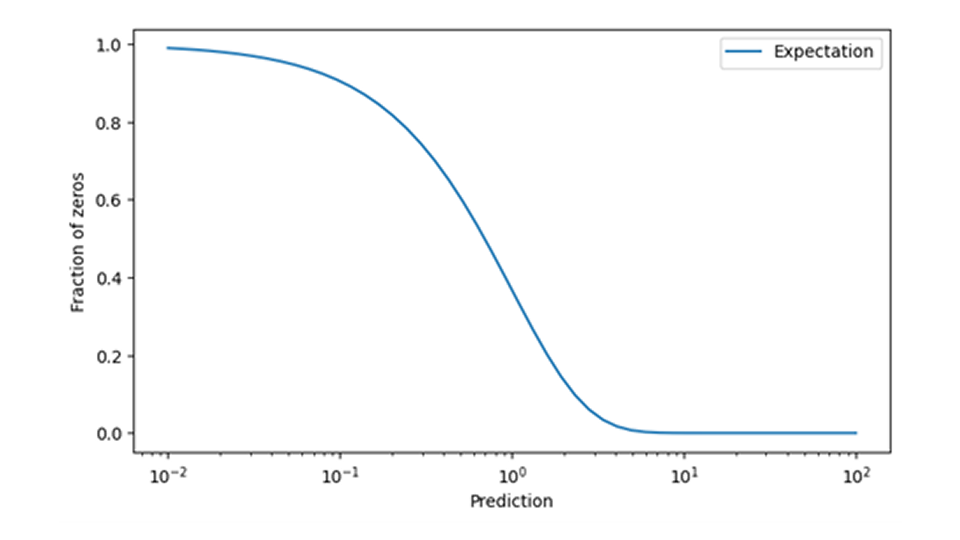
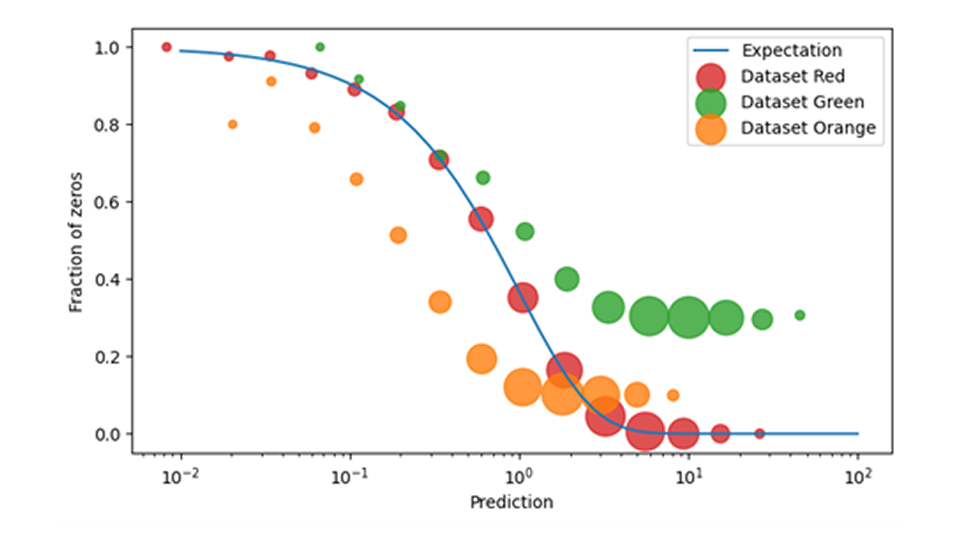
En la previsión de ventas minoristas, los eventos de ventas cero requieren especial atención al capacitar y aplicar modelos de demanda. Es difícil determinar a posteriori si un evento de ventas cero realmente evidencia una demanda que desaparece en un día determinado (como en “nadie tomó ese producto del estante”), o si el producto previsto simplemente no estaba disponible (como en “el producto ni siquiera se colocó en el estante”). Afortunadamente, la coherencia de los datos con el modelo de predicción se puede comprobar comparando la probabilidad prevista de observar cero con la frecuencia observada de eventos de ventas cero. Cuando esos datos no coinciden bien, es decir, cuando se observan ventas cero con mucha más o mucha menos frecuencia de la prevista, se diagnosticó un problema de datos importante pero bien definido.
¿Existe el cero y, de ser así, de cuántas maneras?
El número “cero” eludió la capacidad humana de abstracción durante un tiempo sorprendentemente largo. Las distintas culturas antiguas trataron la “ausencia total de algo” de diferentes maneras, y los historiadores de la ciencia aún debaten cuándo y cómo se inventó el cero como símbolo y se convirtió en parte de la corriente principal de las matemáticas. Por ejemplo, los números romanos ni siquiera contienen un símbolo para el cero, probablemente porque los romanos usaban los números para la contabilidad, no para la aritmética. Aristóteles incluso rechazó la idea misma de que el cero fuera un número: si no se puede dividir por él, ¿para qué sirve? En el siglo VII d.C., el matemático y astrónomo indio Brahmagupta comenzó a emplear y analizar un cero escrito, que luego se extendió al chino y al árabe, y, a través de este último, a la cultura europea.
Por supuesto, conoces el concepto de cero y te sientes cómodo empleándolo. Avancemos rápidamente algunos siglos de discusiones matemáticas hasta la predicción de la demanda minorista empleando aplicaciones de inteligencia artificial (IA) y aprendizaje automático (ML). Sostengo aquí que un solo tipo de cero no es suficiente. Para una correcta descripción de las ventas minoristas, son necesarios al menos dos conceptos diferentes de cero. Uno debe mantener en un conjunto de datos de entrenamiento, el otro debe eliminar.
Por un lado, un producto puede estar disponible y ofrecer al público: la tienda está abierta, la caja registradora y todo lo demás funciona, ¡pero sencillamente ningún cliente quiere comprarlo! En ese caso, el hecho de que no se vendieron productos refleja la falta real de demanda y la falta de interés de los consumidores en ese producto. Idealmente, nuestro modelo de predicción de la demanda no se “sorprende” por ese cero en el sentido de que predijo una probabilidad no microscópica pero finita de observar cero.
La verdadera falta de demanda conduce a una demanda cero, que me gustaría distinguir de la disponibilidad cero. Este último tipo de cero se produce simplemente por la falta de disponibilidad del producto. Al cliente ni siquiera se le ofrece el producto, no tiene ninguna posibilidad de comprarlo, aunque quisiera (nunca lo sabremos). Ayer no vendí ningún iPhone por 99 dólares, pero eso es irrelevante, porque ni siquiera le ofrecí ningún iPhone a nadie. Si lo ofreció, mi precio moderado generó bastante demanda y probablemente encontró un comprador. Tampoco vendí el cochecito usado que ofrecí en línea; eso es más informativo, la demanda es cero. Si bien la demanda cero refleja que el artículo no es particularmente popular (por decirlo suavemente), la falta de disponibilidad cero no tiene nada que ver con la demanda real de un artículo.
La falta de disponibilidad puede tener muchas causas diferentes: la más importante es que las existencias se agotaron; en ese caso, simplemente no queda nada para vender. Por lo tanto, es estupendo tener el valor de las acciones matutinas en una columna bien organizada de nuestros datos. Luego, podemos recurrir a los métodos descritos en esta entrada del blog. Sin embargo, a menudo no nos encontramos con ese paraíso de calidad de datos: la información bursátil no está disponible o, al menos, no es del todo fiable. Pero incluso si se integraran valores de existencias fiables, no podemos estar completamente seguros de que el producto se ofrezca realmente en el estante; podría estar almacenado en la trastienda, el gerente de la tienda podría decidir que es demasiado pronto o demasiado tarde en el año para ofrecerlo.
La falta de disponibilidad oculta la demanda real: Para conocer la demanda de un artículo, necesitamos ofrecerlo. No tengo ni idea de cuánta demanda generará un impermeable verde con motitas rosas, a menos que lo ponga en el estante, le ponga una etiqueta de precio y se lo ofrezca a los clientes. Si un producto no se ofrece, solo puedo formular hipótesis sobre la demanda, pero no puedo medirla.
En resumen, mis conceptos de cero son estos dos: La demanda cero bien gestionada transmite honestamente la información (quizás engañosa) de que el producto en el estante simplemente no es muy popular (por cierto: ¿alguien necesita un cochecito de bebé usado?). y la disponibilidad cero, que oculta toda la información posible sobre la demanda real; esa demanda podría ser cero, uno, 14 o 2766. Es evidente que hay que incluir los valores de demanda cero en el entrenamiento del modelo, pero se sufrirían enormes consecuencias si se confundiera un valor de disponibilidad cero con una falta de demanda.
.png%3Fh%3D480%26iar%3D0%26w%3D640&w=1920&q=75)