
















Se ha hablado mucho de cómo cambiará la IA generativa en la cadena de suministro. En Blue Yonder, queríamos examinar esos impactos a través de un estudio comparativo. En nuestro experimento de investigación, exploramos qué tan capaces son los modelos de lenguaje grandes (LLM) listos para usar, y si se pueden aplicar de manera efectiva al análisis de la cadena de suministro para abordar los problemas reales que enfrenta la gestión de la cadena de suministro.
Los LLM, incluido ChatGPT, son un tipo de inteligencia artificial entrenada con cantidades masivas de datos, lo que les permite aprender los patrones, la gramática y la semántica del lenguaje. En los últimos años, los LLM han experimentado un crecimiento explosivo y se utilizan en una amplia gama de aplicaciones en todo el mundo, como la creación de contenidos, el servicio al cliente y la investigación de mercado.
Los datos de IDC revelan que se prevé que los sectores de software y servicios de información, banca y comercio minorista asignen aproximadamente 89.600 millones de dólares a la IA en 2024, y que la IA generativa representará más del 19% de la inversión total.
Esta tecnología en rápida evolución ofrece a las empresas una mayor creatividad, eficiencia y capacidad de toma de decisiones, que tienen el poder de revolucionar las industrias y los procesos. Entonces, ¿cómo manejan actualmente los LLM las situaciones de la cadena de suministro?
Acerca del estudio de referencia de IA generativa de Blue Yonder
Nuestra prueba de la cadena de suministro de IA generativa se basa libremente en el experimento viral de ChatGPT llamado Examen Uniforme de la Barra. En este estudio, la última versión de ChatGBT aprobó el examen de abogacía con una puntuación combinada alta de 297, acercándose al percentil 90 de todos los examinados. Al superar la barra con una puntuación de casi el 10% superior, los LLM demuestran la capacidad de la IA generativa para comprender y aplicar los principios y regulaciones legales. Este estudio pionero provocó una conversación mundial y puso de relieve el potencial transformador de la IA.
Blue Yonder decidió llevar esta conversación un paso más allá al estudiar cómo los sistemas líderes de LLM podrían funcionar en los exámenes de la industria de la cadena de suministro. Hicimos que los LLM se enfrentaran a dos pruebas de certificación estándar, el CPSM y el CSCP. ¿Nuestro objetivo? Para ver si los LLM podrían funcionar como profesionales de la cadena de suministro, entendiendo las reglas de nicho y el contexto de la industria de la cadena de suministro sin capacitación.
Diseñamos el experimento para ejecutar programáticamente cada LLM a través de las pruebas de práctica, sin contexto en torno a la prueba, sin acceso a Internet y sin capacidad de codificación. Queríamos evaluar el rendimiento de los LLM desde el primer momento, lo que permitiría una evaluación coherente e imparcial.
Tanto el CPSM como el CSCP son de opción múltiple. En lugar de que los LLM simplemente seleccionen una respuesta, configuramos una salida para que los modelos expliquen cada opción que seleccionaron. Este enfoque nos permitió obtener información valiosa sobre el proceso de razonamiento de cada modelo y comprender por qué obtenía respuestas incorrectas o correctas, lo que nos ayudó a evaluar las habilidades de cada modelo.
Después de que se lanzaron las versiones actualizadas de los LLM, volvimos a realizar la prueba este verano para recopilar nuevos resultados de referencia.
Entonces, ¿pueden los LLM aprobar los exámenes de la cadena de suministro?
Sorprendentemente, los LLM se desempeñaron sorprendentemente bien en los exámenes de la cadena de suministro sin ninguna capacitación. Primero analizamos el rendimiento de los LLM listo para usar, sin contexto, y luego agregamos algunas ventajas.
Etapa 1: Sin contexto, sin acceso a Internet, sin capacidad de codificación
Si bien la mayoría de los modelos lograron una calificación aprobatoria sólida sin contexto, Claude 3.5 Sonnet se destacó, asegurando una impresionante precisión del 79.71% en la prueba de certificación CPSM. En el examen CSCP, los modelos o1-Preview y GPT 4o de OpenAI superaron a Claude Opus, con una precisión del 48,30% frente al 45,7% de este último.
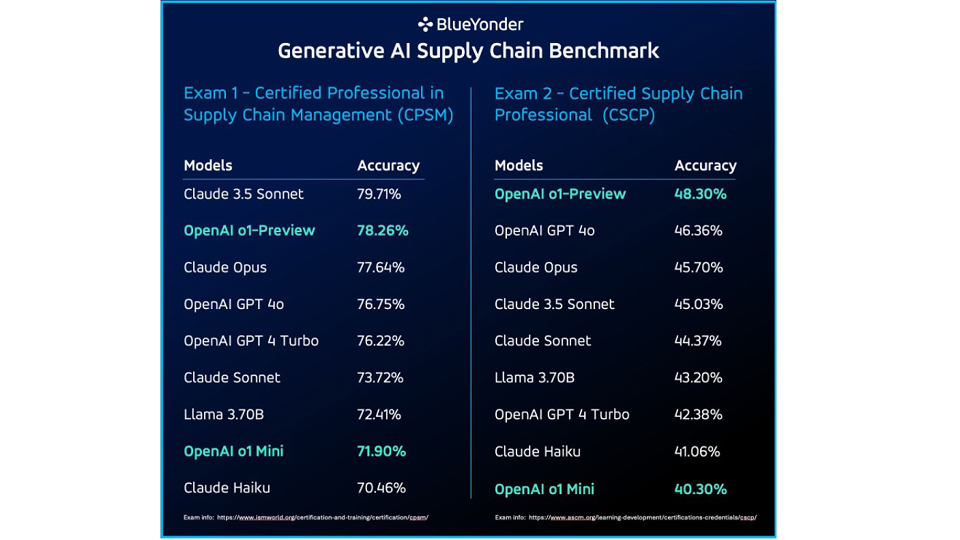
Si bien los LLM se desempeñaron bien en ciertas áreas, también mostraron limitaciones, particularmente cuando se enfrentaron a preguntas relacionadas con las matemáticas o preguntas profundamente específicas del dominio.
Al examinar solo los problemas matemáticos en cada examen de certificación, OpenAI o1 Mini mostró una mejora significativa en la precisión de los modelos OpenAI, superando a los modelos Claude probados.

Estos resultados se generaron sin contexto, sin acceso a Internet y sin capacidad de codificación. A continuación, exploramos qué pasaría si comenzáramos a brindar más asistencia a los LLM.
Etapa 2: Agregar acceso a Internet
En la siguiente etapa de pruebas, les dimos a los programas de LLM acceso a Internet, lo que les permitió buscar usando you.com. Con esa capacidad añadida, OpenAI GPT 4 Turbo logró el avance más significativo -del 42,38% al 48,34%- en la prueba CSCP.
Al observar las preguntas que inicialmente se omitieron en la primera prueba sin contexto, el modelo de Claude Sonnet logró una calificación de precisión de aproximadamente 53.84% para las preguntas CPSM y 20% para las preguntas CSCP.
Si bien el acceso a Internet permitió a los modelos buscar información de forma independiente, también introdujo la posibilidad de imprecisiones debido a fuentes de información en línea poco fiables.
Etapa 3: Proporcionar contexto con RAG
Para la siguiente prueba, utilizamos un modelo RAG (generación aumentada de recuperación), proporcionando a los LLM materiales de estudio de las pruebas. Utilizando RAG, el LLMS superó tanto a las pruebas sin contexto como a las de acceso abierto a Internet en preguntas no matemáticas, logrando las puntuaciones de precisión más altas en ambas pruebas.
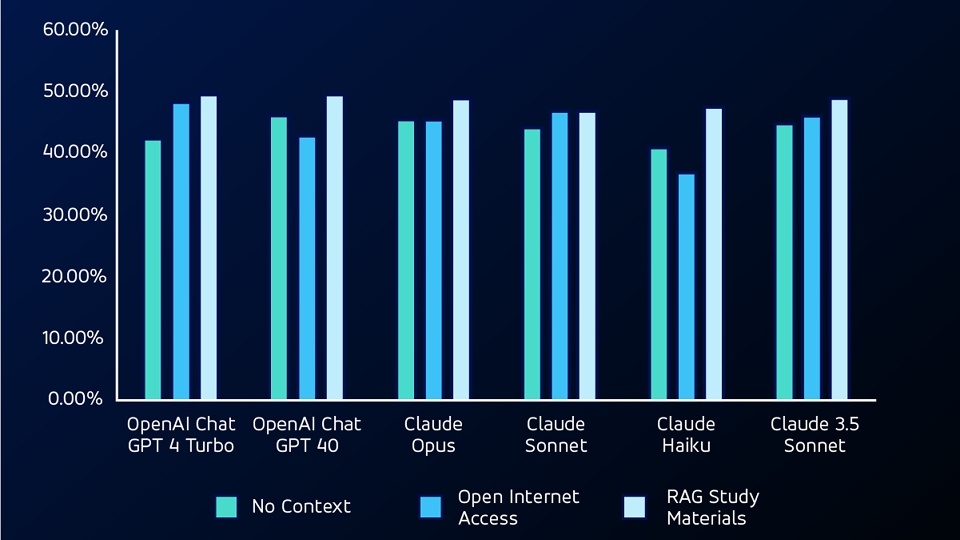
Etapa 4: Adición de habilidades de codificación
Finalmente, para la siguiente prueba, les dimos a los modelos la capacidad de escribir y ejecutar su propio código utilizando los marcos Code Interpreter y Open Interpreter.
Usando estos marcos, los LLM podían escribir código para ayudar a resolver las preguntas matemáticas en los exámenes, con las que lucharon en la primera iteración de la prueba. Con habilidades de codificación, los LLM superaron a la prueba sin contexto en un promedio de aproximadamente el 28% en precisión en todos los modelos para preguntas matemáticas.
¿Son útiles los LLM para resolver problemas de la cadena de suministro?
En general, los sistemas LLM aprobaron los exámenes de cadena de suministro estándar de la industria. Este rendimiento presenta una posibilidad muy emocionante para integrar los LLM en la gestión de la cadena de suministro. Sin embargo, los modelos aún no son perfectos. Tuvieron dificultades tanto con problemas matemáticos como con la lógica específica de la cadena de suministro.
Con la capacidad adicional de escribir código, los LLM pudieron superar muchos de los problemas matemáticos, pero aún necesitaban un contexto de cadena de suministro muy específico para resolver algunas de las preguntas más complejas dentro de los exámenes.
Lo que nuestro estudio reveló es que la IA generativa puede ser extremadamente útil para resolver problemas de la cadena de suministro, con las herramientas y la capacitación adecuadas.
Afortunadamente, eso es en lo que Blue Yonder sobresale. Nos comprometemos a aprovechar el poder de la IA generativa para crear soluciones prácticas e innovadoras para los desafíos de la cadena de suministro. Nuestro recién lanzado AI Innovation Studio es un centro para desarrollar estas soluciones, cerrando la brecha entre las complejas tecnologías de IA y las aplicaciones del mundo real.
Nuestro objetivo es crear agentes inteligentes adaptados a roles específicos dentro de la cadena de suministro, asegurando que estos agentes estén equipados para resolver los problemas y desafíos reales y auténticos a los que se enfrentan en este momento. Obtenga más información sobre la IA y el aprendizaje automático en Blue Yonder, o contáctenos para iniciar una conversación individual.
