¿Qué es un buen pronóstico?
Los pronósticos son como los colegas: la confianza es el factor más importante (nunca quieres que tus colegas te mientan), pero entre tus colegas de confianza, prefieres reunirte con aquellos que te cuentan las historias más interesantes.
¿Qué quiero decir con esta metáfora? Queremos que las previsiones sean “buenas”, “exactas” y “precisas”. Pero, ¿qué queremos decir con eso? Vamos a afinar nuestras ideas para articular y visualizar mejor lo que esperamos de un pronóstico. Existen dos formas independientes de medir la calidad de un pronóstico, y es necesario considerar ambas —calibración y precisión— para comprender satisfactoriamente su rendimiento.
Calibración de pronóstico
Para simplificar, comencemos con la clasificación binaria: el resultado pronosticado solo puede tomar dos valores, “verdadero o falso”, “0 o 1”, o similares.
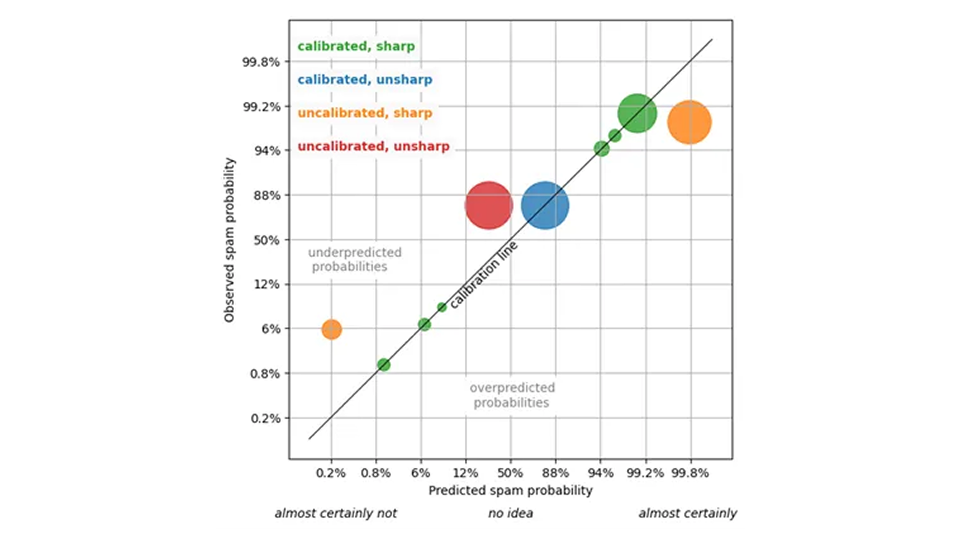
Para ser más concretos, consideremos los emails y si el usuario de su buzón los marcará como spam. Un sistema predictivo genera, para cada email, un porcentaje de probabilidad de que este correo sea considerado spam por el usuario (lo que tomamos como referencia). Por encima de cierto umbral, digamos el 95%, el email acaba en la carpeta de spam.
Para evaluar este sistema, puede, en primer lugar, comprobar la calibración del pronóstico: para aquellos emails a los que se les asigna una probabilidad de spam del 80%, la fracción de spam verdadero debería rondar el 80% (o al menos no diferir de forma estadísticamente significativa). Para aquellos emails a los que se les asignó una probabilidad de spam del 5%, la fracción de spam verdadero debería ser de alrededor del 5%, y así sucesivamente. Si esto es así, podemos confiar en el pronóstico: una supuesta probabilidad del 5% es, en efecto, una probabilidad del 5%.
Una previsión calibrada nos permite tomar decisiones estratégicas: por ejemplo, podemos establecer el umbral de la carpeta de spam adecuadamente y podemos estimar el número de falsos positivos/falsos negativos por adelantado (es inevitable que algo de spam llegue a la bandeja de entrada y que algunos emails importantes acaben en la carpeta de spam).
Precisión de pronóstico
¿Es la calibración el único método para predecir la calidad? ¡No exactamente! Imaginemos un pronóstico que asigne una probabilidad general de spam del 85% a cada email. Esa previsión está bien calibrada, ya que el 85% de todos los emails son spam o maliciosos. Puedes confiar en esa predicción; no te está mintiendo, pero es bastante inútil: no puedes tomar ninguna decisión útil basándote en la afirmación trivial y repetida de que “la probabilidad de que este email sea spam es del 85%”.
Un pronóstico útil es aquel que asigna probabilidades muy diferentes a distintos emails: 0,1% de probabilidad de spam para el email de tu jefe, 99,9% para anuncios farmacéuticos dudosos, y que permanece calibrado. Los estadísticos denominan a esta propiedad de utilidad «agudeza» , ya que se refiere a la amplitud de la distribución prevista de resultados, dada una predicción: cuanto más estrecha, más aguda.
Un pronóstico no individualizado que siempre produce una probabilidad de spam del 85% es sumamente impreciso. La máxima nitidez significa que el filtro de spam asigna solo un 0% o un 100% de probabilidad de spam a cada email. Este grado máximo de precisión –determinismo– es deseable, pero irreal: dicha predicción (muy probablemente) no estará calibrada, y algunos emails marcados con un 0% de probabilidad de spam resultarán ser spam, y algunos emails marcados con un 100% de probabilidad de spam resultarán ser de tu pareja.
¿Cuál es entonces el mejor pronóstico? No queremos renunciar a la confianza, por lo que el pronóstico debe mantener calibrado, pero dentro de los pronósticos calibrados, queremos el más preciso. Este es el paradigma de pronóstico probabilístico, que fue formulado por Gneiting, Balabdaoui y Raftery en 2007 (J. R. Estadístico. Soc. B 69, Parte 2, págs. 243–268): Maximice la nitidez, pero no ponga en peligro la calibración. Haz la afirmación más contundente posible, siempre que siga siendo cierta. Como con nuestros colegas, cuéntame la historia más interesante, pero no me mientas. Para un filtro de spam, el pronóstico más preciso asigna valores como el 1% a los emails que claramente no son spam, el 99% a los emails que claramente son spam y algún valor intermedio a los casos difíciles de decidir (de los cuales no debería haber demasiados).